Daten mit dem Heapsort-Algorithmus sortieren
Um Daten in einem Computerprogramm zu sortieren, bestehen zahlreiche verschiedene Möglichkeiten. Diese weisen jedoch ganz unterschiedliche Eigenschaften auf. Daher ist es wichtig, verschiedene Verfahren kennenzulernen und für jede Anwendung einen passenden Algorithmus auszuwählen. Dieser Artikel stellt das Heapsort-Verfahren vor.

Wie funktioniert der Heapsort-Algorithmus?
Der Heapsort-Algorithmus wird häufig als eine Weiterentwicklung des Selectionsort-Verfahrens beschrieben, das wir in unserer Reihe zu den Sortieralgorithmen bereits vorgestellt haben. Daher ist es empfehlenswert, zunächst den entsprechenden Artikel zu lesen. Kurz zusammengefasst kann man sagen, dass Selectionsort je nach Umsetzung das kleinste oder das größte Element der Liste sucht und dieses dann an die erste beziehungsweise an die letzte Stelle setzt. Danach geht der Algorithmus den übrigen Teilbereich der Liste durch, um das zweitkleinste oder das zweitgrößte Element zu finden. Dieses setzt er dann an die zweite beziehungsweise an die vorletzte Stelle. Nach diesem Muster geht er dann die komplette Liste durch, bis diese vollständig sortiert ist. Das Vorgehen beim Heapsort-Algorithmus ist ähnlich. Allerdings nimmt dieser zunächst eine Änderung der Struktur der Liste vor und organisiert diese als Heap. Das macht es später einfacher, das kleinste oder das größte Element zu finden. Auf diese Weise kommt es im Vergleich zu Selectionsort zu einer deutlichen Erhöhung der Effizienz.
Begriffserklärung: Binärbäume und Heaps
Um den Heapsort-Algorithmus zu verstehen, ist es wichtig, zunächst zu klären, was ein Heap ist. Dieser Begriff stammt aus dem Englischen und bedeutet übersetzt Haufen oder Halde. Bei einem Heap handelt es sich um eine spezielle Form des Binärbaums. Daher ist es sinnvoll, zunächst diese Datenstruktur zu beschreiben.
Wenn man in der Informatik von einem Baum spricht, bezieht sich dieser Begriff auf die Organisation von Daten. Ein Baum weist ein Wurzelelement auf, das der Ausgangspunkt für alle weiteren Daten ist. Die Wurzel kann mehrere Kind-Elemente aufweisen. Dabei gibt es außerdem mehrere Ebenen. Das soll die folgende Abbildung darstellen.
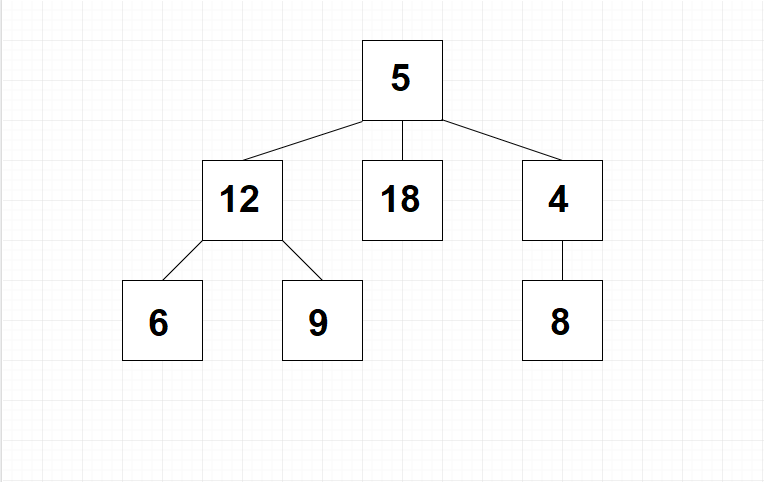
Besonders oft kommen hierbei Binärbäume zum Einsatz. Das bedeutet, dass jedes Element maximal zwei Kind-Elemente aufweisen darf. Eine weitere Untergruppe wird hierbei als kompletter Binärbaum bezeichnet. Hierbei gilt zusätzlich die Vorgabe, dass alle Ebenen mit Ausnahme der letzten komplett ausgefüllt sein müssen. Sollte es bei der letzten Ebene aufgrund der gewählten Anzahl der Elemente nicht möglich sein, diese vollständig auszufüllen, müssen sich die freien Bereiche am rechten Rand befinden. Die folgende Abbildung zeigt einen kompletten Binärbaum.
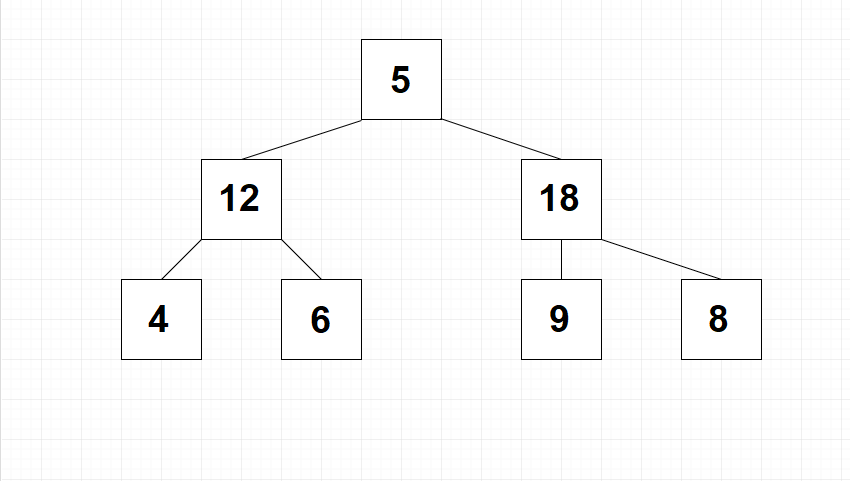
Ein Heap ist stets als kompletter Binärbaum organisiert. Allerdings gilt hierbei noch eine weitere Anforderung. Bei einem Heap muss jeder Knotenpunkt größer sein als seine Kind-Elemente. Darüber hinaus ist es auch möglich, diese Vorgabe umzukehren – also dass jeder Knotenpunkt kleiner als seine Kind-Elemente sein muss. Um diese Fälle voneinander abzugrenzen, kommen auch die Bezeichnungen MaxHeap und MinHeap zum Einsatz. Der Heapsort-Algorithmus lässt sich mit beiden Formen umsetzen. In unseren weiteren Beispielen arbeiten wir jedoch stets mit einem MaxHeap. Die folgende Abbildung zeigt eine mögliche Verteilung der Werte.
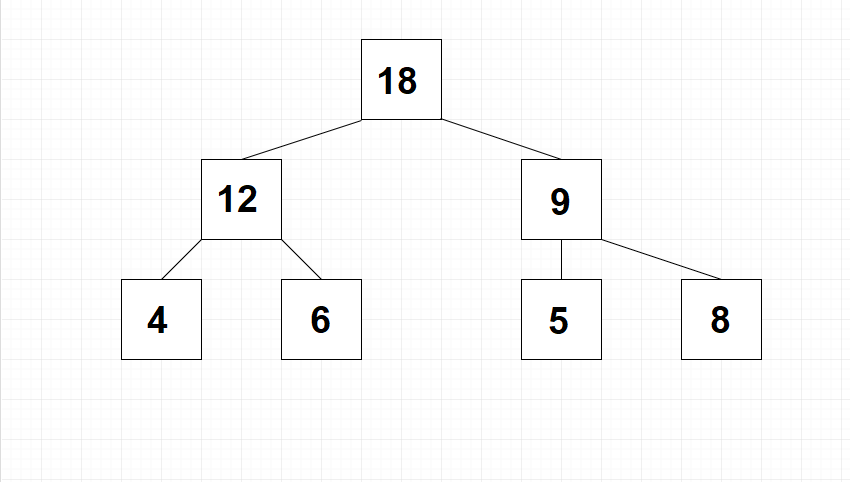
Die Daten in einen Heap übertragen
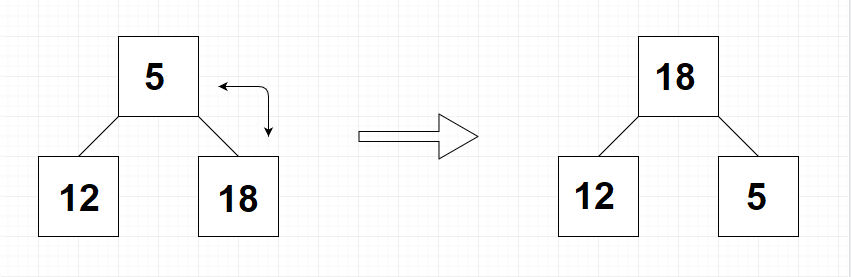
Der Heapsort-Algorithmus überträgt zunächst den ungeordneten Datensatz in einen Heap. Das stellt eine gewisse Vorsortierung dar, für die jedoch im Vergleich zu einer vollständigen Sortierung nur wenige Operationen notwendig sind. Um die Vorgehensweise zu verstehen, betrachten wir zunächst einen einzelnen Knotenpunkt mit seinen beiden Kind-Elementen. In diesem Fall ist es ganz einfach, aus diesen drei Werten ein Heap zu erzeugen. Hierfür müssen wir lediglich bestimmen, welcher dieser drei Werte der größte ist. Wenn es sich hierbei um das Eltern-Element handelt, ist keine weitere Aktion notwendig, da die Daten bereits nach den Regeln des Heaps geordnet sind. Handelt es sich beim größten Element hingegen um eines der Kind-Elemente, ist es notwendig, dessen Position mit der des Eltern-Elements zu vertauschen. Das zeigt die folgende Abbildung.
Um den kompletten Datensatz entsprechend zu ordnen, beginnen wir bei der untersten Ebene. Danach arbeiten wir uns Knoten für Knoten zu den oberen Ebenen vor. Diese Vorgehensweise hat zur Folge, dass sichergestellt ist, dass die Ebenen unterhalb des Knotenpunkts, den wir bearbeiten, bereits als Heap organisiert sind.
Dabei tritt jedoch das Problem auf, dass der Austausch eines Werts auf einer höheren Ebene die darunterliegenden Bereiche ebenfalls beeinflussen kann. Das heißt, dass wir diese ebenfalls neu ordnen müssen. Daher müssen wir den Bereich, der davon betroffen ist, erneut nach den Regeln eines Heaps organisieren. Dabei können wir jedoch bei dem Knotenpunkt beginnen, in dem sich bislang das größte Element befand. Auf die übrigen Zweige hat die Veränderung keine Auswirkung. Die folgende Abbildung zeigt, wie das entsprechende Element dann in mehreren Schritten in die richtige Ebene verschoben wird.
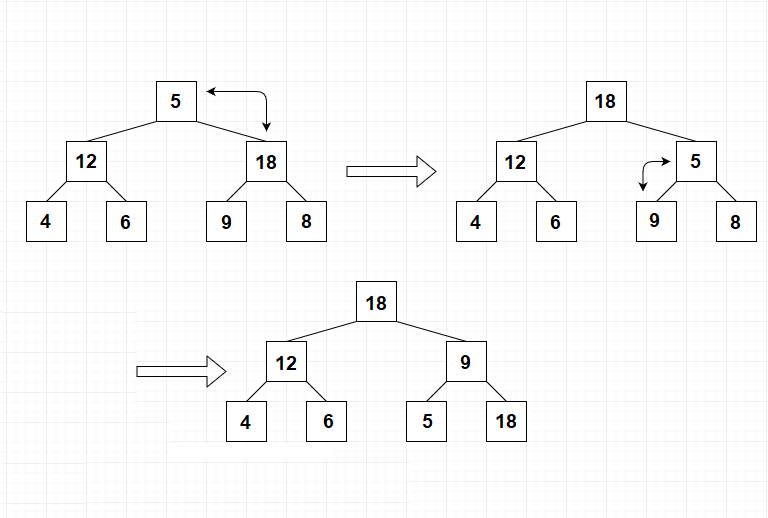
Dieser Vorgang ist jedoch nur dann notwendig, wenn wir die Position des Elements vertauschen mussten. Ist dies nicht der Fall, ist weiterhin gewährleistet, dass auch alle unteren Ebenen nach dem Heap-Prinzip geordnet sind. Wenn wir uns nach diesem Verfahren bis zum Wurzelelement vorgearbeitet haben, ist sichergestellt, dass der komplette Datensatz die entsprechenden Vorgaben erfüllt.
Die Werte aus dem Heap in die Liste einordnen
Wenn wir die Daten nach der beschriebenen Methode geordnet haben, ist dabei eine Vorsortierung gegeben. Dennoch sind die Daten noch nicht vollständig sortiert. Allerdings ist die Sortierung der Werte nach dieser Vorarbeit ganz einfach. Dazu führen wir uns nochmals das Prinzip des Selectionsort-Algorithmus vor Augen. Dabei gehen wir von der Implementierungsweise aus, die das größte Element der Liste sucht und dieses an die letzte Stelle setzt. Dazu muss das Programm jedoch für jede Position die komplette Liste durchgehen. Das ist sehr ineffizient.
Um den Vorgang effizienter zu gestalten, greifen wir nun auf unsere Heap-Struktur zurück. Diese stellt sicher, dass es sich beim Wurzelelement um den größten Wert der Liste handelt. Auf dieses Wurzelelement können wir ganz einfach zugreifen – es befindet sich immer an der ersten Position der Liste.
Hinweis: Es wäre auch möglich, genau die umgekehrte Vorgehensweise zu verwenden und das kleinste Element an die erste Stelle zu verschieben – analog zum Verfahren, das im Artikel zum Selectionsort-Verfahren vorgestellt wurde. Das würde es jedoch notwendig machen, zunächst ein MinHeap statt ein MaxHeap zu erstellen.
Die Entfernung des Wurzelelements kann dazu führen, dass die übrigen Werte nicht mehr nach der Heap-Struktur organisiert sind. Daher ist es nun notwendig, die entsprechende Strukturierung erneut vorzunehmen – allerdings mit Ausnahme des letzten Array-Felds, da wir dieses bereits endgültig sortiert haben.
Auf diese Weise bearbeiten wir nun den gesamten Datensatz. Dabei entfernen wir immer das Wurzelelement und füllen damit die Liste von hinten auf. Nach jeder Veränderung organisieren wir die Daten erneut nach dem Heap-Prinzip – jedoch nur den Bereich, den wir noch nicht endgültig sortiert haben.
Ein Beispielprogramm für Heapsort
Nachdem die grundsätzliche Funktionsweise des Heapsort-Algorithmus vorgestellt wurde, soll nun noch ein praktisches Beispiel folgen. Hierfür verwenden wir die Programmiersprache C.
Vorüberlegung: Wie werden Heaps in einem Array dargestellt?
In C gibt es keine eigene Datenstruktur für Bäume oder Heaps – genau wie in den meisten anderen Programmiersprachen auch. Wenn wir mehrere Daten gemeinsam speichern möchten, kommen hierfür in erster Linie Arrays zum Einsatz. Daher ist es wichtig, sich zu überlegen, auf welche Weise es möglich ist, Heaps in einem Array darzustellen.
Hierfür gehen wir davon aus, dass sich das Wurzel-Element an der ersten Stelle des Arrays befindet – also im Feld mit dem Index 0. Danach folgen die beiden ersten Kind-Elemente. Diese stehen daher an den Positionen 1 und 2. Daran schließt sich dann die nächste Ebene an. Die Kind-Elemente des Knotens an Position 1 belegen daher die Positionen 3 und 4. Die Kind-Elemente des Knotens an Position 2 speichern wir demnach in den Feldern 5 und 6 ab.
Aus dieseAus dieser Vorgehensweise lässt sich ein allgemeines Muster ableiten. Wenn wir davon ausgehen, dass wir die Position eines Elements mit der Variable i bezeichnen, erreichen Sie das erste Kind-Element, indem Sie die Position dieses Elements verdoppeln und den Wert 1 hinzuaddieren – also nach der Formel 2*i + 1. Das zweite Kind-Element erreichen Sie dementsprechend über die Formel 2*i + 2.
Die Funktion heapSort(): Grundlage des Sortieralgorithmus
Nach dieser Vorüberlegung beginnen wir mit der Programmerstellung. Dabei implementieren wir zunächst die Funktion HeapSort(). Das Hauptprogramm soll diese später aufrufen, um das Array zu sortieren. Es erhält als Übergabewerte sowohl das Array als auch dessen Größe.
Die erste Aufgabe besteht darin, das gesamte Array als Heap zu organisieren. Es wurde bereits ausgeführt, dass wir hierfür immer ein Eltern-Element mit seinen beiden Kind-Elementen vergleichen müssen. Als Referenzpunkt nehmen wir daher stets das entsprechende Eltern-Element. Das bedeutet, dass wir diesen Prozess nur auf die Elemente in der ersten Hälfte des Arrays anwenden müssen. Bei den Elementen in der zweiten Hälfte handelt es sich um Knotenpunkte, die keine Kind-Elemente haben. Für jedes Feld in der ersten Array-Hälfte rufen wir die Funktion heapify() auf. Diese erstellen wir später. Ihre Aufgabe besteht darin, die einzelnen Knotenpunkte nach den Regeln eines Heaps zu organisieren. Die for-Schleife, die wir hierfür erstellen müssen, sieht demnach wie folgt aus:
Wenn das Array als Heap strukturiert ist, besteht der nächste Schritt darin, es zu ordnen. Da unsere Heap-Struktur sicherstellt, dass sich das größte Element ganz am Anfang befindet, können wir dieses nun einfach mit dem Element an der letzten Stelle austauschen. Das führt dazu, dass sich das größte Element ganz am Ende des Arrays und damit an der richtigen Stelle befindet.
Im nächsten Schritt möchten wir das zweitgrößte Element an die vorletzte Stelle setzen. Da durch das Entfernen des Wurzelelements nicht mehr gewährleistet ist, dass die Werte nach dem Heap-Prinzip geordnet sind, müssen wir die entsprechende Strukturierung erneut vornehmen. Allerdings wenden wir die Methode heapify() nun nicht mehr auf das ganze Array an. Das letzte Feld ist bereits mit seinem endgültigen Wert belegt, sodass wir dieses nicht mehr verändern. Um das letzte Feld von der Neustrukturierung auszunehmen, setzen wir die Angabe der Array-Größe um 1 niedriger, als dieses eigentlich ist.
Durch die erneute Strukturierung ist gewährleistet, dass sich nun das zweitgrößte Element an der ersten Stelle des Arrays befindet. Daher können wir dieses mit dem Element an der vorletzten Stelle austauschen. Nach diesem Prinzip gehen wir nun das gesamte Array durch. Das führt zu folgender Schleife:
Damit ist die Funktion heapSort() abgeschlossen. Ihr kompletter Code sieht wie folgt aus:
Einen Heap mit der Funktion heapify() erstellen
Eine zentrale Aufgabe im Heapsort-Algorithmus führt die Funktion heapify() aus. Diese strukturiert das Array als Heap. Dazu benötigt sie selbstverständlich das Array als Übergabewert. Außerdem wird die Größe des Arrays benötigt – beziehungsweise des Bereichs, den wir noch nicht endgültig sortiert haben. Außerdem müssen wir die Position angeben, an der wir beginnen möchten.
Bei dem angegebenen Feld handelt es sich um das Eltern-Element. Zunächst nehmen wir an, dass die Werte bereits die Heap-Struktur befolgen und dass das Eltern-Element daher größer als die Kind-Elemente ist. Daher weisen wir dessen Position der Variable groesstesElement zu. Danach bestimmen wir nach der oben beschriebenen Formel die Positionen der beiden Kind-Elemente.
Nun müssen wir noch überprüfen, ob eines der beiden Kind-Elemente größer ist als das Eltern-Element. In diesem Fall weisen wir der Variable groesstesElement die entsprechende Position zu. Hierbei ist es nicht nur notwendig, zu ermitteln, ob der Wert des Kind-Elements größer ist als der des Eltern-Elements. Darüber hinaus müssen wir sicherstellen, dass das Kind-Element überhaupt existiert. Das erreichen wir, indem wir überprüfen, ob es innerhalb der vorgegebenen Array-Größe liegt. Das führt zu den beiden folgenden Abfragen:
Wenn das Eltern-Element bereits größer als die beiden Kind-Elemente ist, ist keine weitere Aktion erforderlich. Nur wenn diese Vorgabe nicht erfüllt ist, müssen wir die Werte neu ordnen. Daher stellen wir den anschließenden Bereich in eine if-Abfrage mit der folgenden Bedingung:
if (groesstesElement != position)
Wenn eines der Kind-Elemente größer als das Eltern-Element ist, tauschen wir die beiden Werte aus. In diesem Fall kann diese Änderung jedoch auch Auswirkungen auf die darunter liegenden Ebenen haben. Daher müssen wir erneut die heapify()-Funktion für den entsprechenden Bereich aufrufen – allerdings nur für das Kind-Element, das wir ausgetauscht haben. Das macht auch deutlich, dass es sich hierbei um einen rekursiven Algorithmus handelt – dass sich die Funktion also selbst aufruft. In die if-Abfrage stellen wir daher die folgenden Befehle:
Das Hauptprogramm erstellen
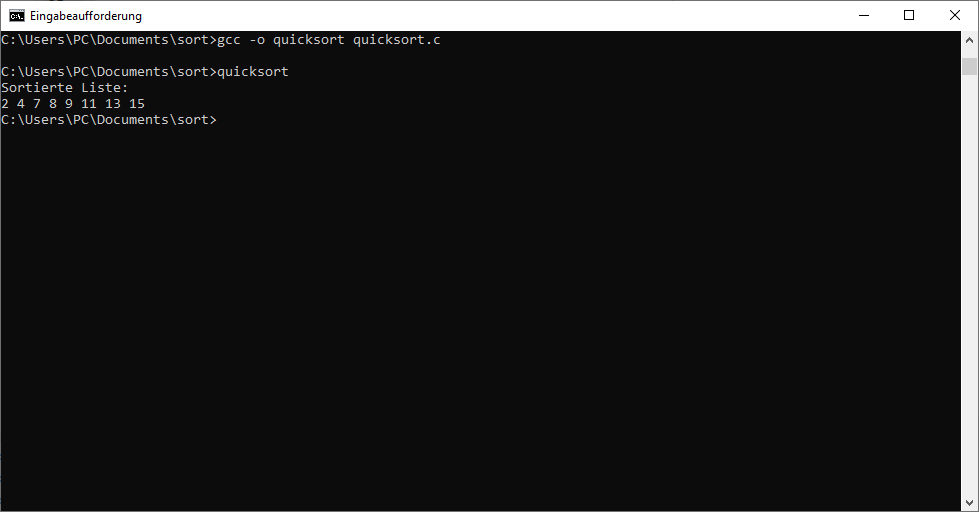
Der letzte Schritt besteht darin, das Hauptprogramm zu erstellen. Hier erzeugen wir lediglich ein Array und bestimmen dessen Größe mit der sizeof()-Funktion. Danach rufen wir die heapSort()-Funktion auf. Anschließend geben wir noch das sortierte Array aus:
Nun lässt sich das Programm auch ausführen. Das Ergebnis ist in der folgenden Abbildung zu sehen.
Wie effizient arbeitet der Heapsort-Algorithmus?
Zum Abschluss ist es sinnvoll, einen Blick auf die Effizienz dieses Algorithmus zu werfen und diese mit anderen Sortieralgorithmen zu vergleichen.
Die Zahl der erforderlichen Rechenoperationen lässt sich hierbei mit der Formel n*log(n) bestimmen – sowohl im Durchschnitts-Fall als auch im besten und im schlechtesten Fall. Damit weist der Heapsort-Algorithmus im besten und im durchschnittlichen Fall die gleichen Werte wie der beliebte Quicksort-Algorithmus auf, den wir in dieser Reihe ebenfalls bereits vorgestellt haben. Bei Listen mit einer sehr ungünstigen Verteilung arbeitet er jedoch wesentlich effizienter. Während die Komplexität beim Quicksort-Algorithmus in diesem Fall einer quadratischen Funktion folgt, handelt es sich beim Heapsort-Algorithmus selbst bei einer ungünstigen Verteilung um eine Funktion der Ordnung n*log(n). Das bedeutet, dass es damit möglich ist, Listen auf eine sehr effiziente Weise zu sortieren.