Web Scraping mit Python
Web Scraping (auch Web Data Mining oder Web Harvesting genannt) bezeichnet den Prozess, Daten aus dem Internet automatisiert zu extrahieren, aufzubereiten und zu analysieren. Die Praktik gehört damit in den Bereich der Data Science, genauer des Data Minings. Web Scraping ist ein idealer Einstiegspunkt für Anfänger, um zu verstehen, wie man mit der schier unendlichen Datenflut im Netz umgehen kann. In diesem Artikel wollen wir daher genauer darauf eingehen, wie Web Scraping funktioniert, und einen eigenen Web Scraper in Python umsetzen.
Was genau ist Web Scraping?
Stellen Sie sich vor, Sie besuchen einen Webshop und suchen alle Artikel unter einem bestimmten Preis: Sie können die relevanten Produkte einzeln heraussuchen und händisch kopieren. Das ist allerdings ein sehr langwieriger und bei komplexeren Aufgaben fehleranfälliger Prozess. Alternativ könnten Sie ein Programm schreiben, das den Inhalt des Shops analysiert und die gesuchten Informationen ausliest. Ein solches Programm wird Web Scraper genannt und arbeitet nach den folgenden Schritten:
- Inhalte herunterladen: Der erste Schritt des Web Scraping ist es, die Webseite(n) aufzurufen und die Inhalte herunterzuladen. Meistens liegen die Informationen im HTML-Format vor. Die unaufbereiteten Daten werden als Raw Data bezeichnet.
- Daten transformieren / extrahieren: Nachdem die Rohdaten heruntergeladen wurden, müssen sie aufbereitet bzw. die gesuchte Information extrahiert werden. Dazu werden beispielsweise bestimmte HTML-Elemente selektiert oder der Inhalt der Webseite wird mit regulären Ausdrücken gefiltert.
- Weitere Verwendung der Daten: Nachdem die Daten aufbereitet wurden, können Sie für einen beliebigen Zweck verwendet werden – beispielsweise, indem man sie in einer Datenbank abspeichert, aggregiert oder für die Erstellung von Statistiken nutzt. Dazu können weitere Transformationsschritte durchgeführt werden.
Anwendungen von Web Scraping
Web Scraping hat mehr oder minder unendlich viele Anwendungen. Einige davon sind:
- E-Commerce: Im E-Commerce kann Web Scraping dazu verwendet werden, eine Übersicht über aktuelle Angebote und Preistrends zu erhalten – sowohl wie eben beschrieben als Endkunde, als auch als Unternehmen, um die Daten der Konkurrenz zu analysieren.
- Marketingkampagnen: Ebenso kann Web Scraping für Marketingkampagnen verwendet werden, indem Userdaten wie E-Mail-Adressen, Telefonnummern oder Homepages von Seiten wie LinkedIn oder YellowPages gesammelt werden.
- Research: Forschungsprojekte können Web Scraping nutzen, um insbesondere generische Informationen aus verschiedenen Quellen zu sammeln und zu aggregieren.
- Privatbereich: Im Privatbereich kann Web Scraping für verschiedene Anwendungen genutzt werden, die das Leben erleichtern. So wäre es beispielsweise möglich, die wichtigsten Nachrichten von verschiedenen Webseiten zusammenzufassen oder Aufgaben, die man für gewöhnlich Schritt für Schritt durchführen muss, zu automatisieren.
Das gibt es bei Web Scraping zu beachten
Wichtig für Web Scraping aller Art ist es, sich über die rechtlichen Aspekte im Klaren zu sein: Für den Privatgebrauch ist Web Scraping fast immer erlaubt oder hat zumindest keine rechtlichen Konsequenzen. Sollen die Daten allerdings veröffentlich werden, beispielsweise im Rahmen eines Forschungsprojektes, müssen die Richtlinien der jeweiligen Webseite beachtet werden – gegebenenfalls, indem man den Besitzer bzw. den Autor der Seite kontaktiert.
Neben der rechtlichen Lage ist es wichtig, den Server, von dem man scrapen will, nicht zu überlasten. Werden sehr viele Requests in kurzer Zeit gestellt, kann die Webseite den Traffic eventuell nicht händeln und wird damit lahmgelegt. Manche Webseiten sperren den Zugriff einer IP-Adresse auch, wenn zu viele Requests in einem bestimmten Zeitintervall gesendet werden. Das soll illegale Aktivitäten unterbinden. Eine Möglichkeit, eine solche Sperre oder Überlastung zu vermeiden, ist es, die Anfragen in einer Schleife mit kurzen Warteperioden auszuführen.
Ein eigener Web Scraper mit Python
Nachdem wir nun wissen, was Web Scraping ist, werden wir in diesem Tutorial einen eigenen Web Scraper mit Python implementieren. Das Ziel wird sein, alle Mathematiker des 19. Jahrhunderts, die vor ihrem 60. Geburtstag gestorben sind, aus Wikipedia zu ermitteln. Sie sollten für dieses Tutorial sowohl Grundkenntnisse in HTML, CSS und JavaScript besitzen als auch die Grundkonzepte und Syntax der Programmierung mit Python und von regulären Ausdrücken kennen.
Warum Python?
Python ist eine der beliebtesten Sprachen, um Web Scraper zu implementieren. Das hat verschiedene Gründe: Zum einen ist Python eine relativ simple Sprache, mit der man Programme ohne viel Setup schreiben kann. Gerade, wenn der Web Scraper nur ein kleines Tool für einen bestimmten Zweck sein soll, ist es praktisch, das Projekt schnell aufsetzen zu können. Zum anderen hat Python sehr viele Module, die die wichtigsten Funktionen für Web Scraping Out-Of-The-Box zur Verfügung stellen. Das gilt im Übrigen nicht nur für Web Scraping: Auch für andere Themen aus den Bereichen Data Science, Statistik oder KI stellt Python sehr viel Funktionalität durch Bibliotheken zur Verfügung.
Das Projekt
Das Ziel des Tutorials wird es sein, aus dem Wikipedia-Artikel über alle Mathematiker des 19. Jahrhunderts diese zu finden, die nicht älter als 60 Jahre alt geworden sind. Dazu müssen zuerst Python und einige Bibliotheken installiert werden. Anschließend ermitteln wir eine Strategie, um an die gewünschten Informationen zu kommen und setzen diese mit Python um.
Schritt 1: Python-Installation und Setup
Installieren Sie eine Python-Version von https://www.python.org/downloads/. Laden Sie den Installer herunter und führen ihn aus. Erlauben Sie, dass Python dem Pfad (PATH) hinzugefügt wird und führen danach die reguläre Installation durch.
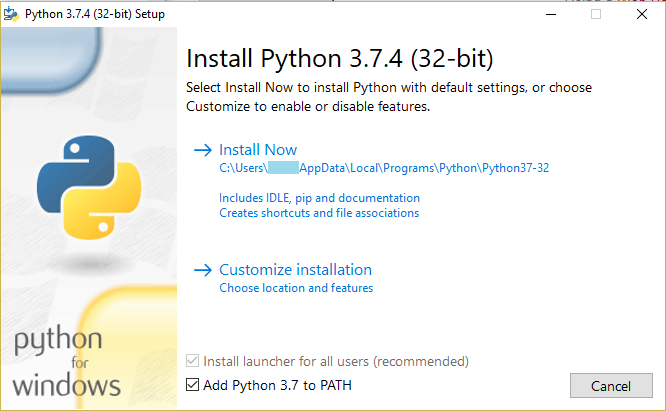
Sie können verifizieren, dass die Installation erfolgreich war, indem Sie in der Kommandozeile
python –-version
aufrufen.

Als nächsten installieren wir die Module, die für Web Scraping benötigt werden. Dazu nutzen wir pip, den Package Installer für Python. Dieser ist bereits mit Python installiert worden. In einer Kommandozeile geben Sie den Befehl
pip install <module_name>
ein. Sollte die Installation fehlschlagen, weil Ihnen Zugriffsrechte fehlen, müssen Sie die Kommandozeile noch einmal als Administrator starten.
Die benötigten Module für dieses Tutorial sind:
- Urllib3: Urllib3 ist ein HTTP-Client für Python, durch den Anfragen an Webseiten gestellt werden können.
- Requests: Requests ist ebenfalls eine Bibliothek, um HTTP-Anfragen zu senden. Wie viele andere HTTP-Module setzt Requests auf Urllib3 auf. Der Vorteil von Requests gegenüber der Nutzung von Urllib3 ist, dass Aufrufe abstrahiert werden und damit einfacher zu verstehen und zu programmieren sind. Requests ist damit zwar weniger mächtig, nimmt dem Nutzer dafür aber einiges an Arbeit ab. Da Requests auf Urllib3 aufbaut, reicht für die Installation der Befehl:
pip install requests
- BeautifulSoup: BeautifulSoup ist eine Bibliothek, um Daten aus HTML- und XML-Dateien zu extrahieren. Dazu erstellt BeautifulSoup einen Parse-Tree, der das Dokument repräsentiert. Ein Parse-Tree ist eine Datenstruktur, die einfache Navigation und Manipulation ermöglicht und damit die Komplexität des unterliegenden Dokuments verbirgt. Wenn Sie Python 3 oder höher installiert haben, müssen Sie nicht beautifulsoup sondern beautifulsoup4 installieren:
pip install beautifulsoup4
Schritt 2: Analyse der Webseite
Damit der Web Scraper Daten automatisiert erfassen kann, muss er Wissen über die Struktur der Seite, die gescraped werden soll, besitzen. Wir müssen uns also zum einen mit dem Seitenaufbau vertraut machen und zum anderen einen Plan entwickeln, wie wir aus diesem Aufbau automatisiert die gewünschte Information ermitteln können. Öffnen Sie dazu den Wikipedia-Artikel über alle Mathematiker, die im 19. Jahrhundert geboren wurden.
Stellen wir zuerst fest, dass jeder Mathematiker mit seinem Namen und dahinter in Klammern seinem Geburts- und Sterbejahr aufgeführt wird. Bei manchen Einträgen ist zudem noch eine zusätzliche Information hinter den Jahreszahlen angestellt.
Ein Ansatz könnte für uns also sein, die einzelnen Aufzählungspunkte zu erfassen und anschließend die Differenz der in Klammern stehenden Zahlen zu ermitteln. Doch wie kommen wir an diese Elemente? Dazu kann der Inspektor des Browsers verwenden werden. Der Inspektor erlaubt es, das HTML einer Webseite zu untersuchen, zu verändern und auch den Netzwerktraffic oder die Performance der Seite zu untersuchen. Um den Inspektor zu öffnen, klicken Sie mit der rechten Maustaste auf die Seite und wählen „Untersuchen“.
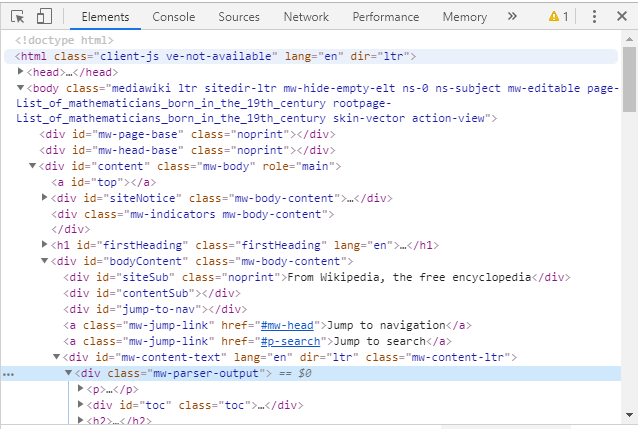
Einen Inspektor gibt es in jedem Browser, in diesem Tutorial wird allerdings Chrome verwendet.
In der Ecke des Inspektors befindet sich ein Icon:

Nachdem Sie auf dieses Icon geklickt haben, können Sie im Browser mit der Maus über beliebige Elemente fahren und mit Rechtsklick zu der entsprechenden Stelle im HTML springen.

Wir sehen, dass die einzelnen Stichpunkte, die die Mathematiker enthalten, li-Elemente sind. Das heißt, wir können zuerst alle List Items aus dem HTML extrahieren und anschließend aufbereiten. Mit dieser Information können wir mit der Implementierung beginnen.
Schritt 3: Den Web Scraper implementieren
Legen Sie eine Datei webscraper.py an und öffnen Sie sie mit der Python IDLE. So erhalten Sie einen leeren Editor. Wenn Sie bereits mit Python gearbeitet haben und eine andere Methode oder einen anderen Editor bevorzugen, können Sie natürlich auch diesen verwenden.
Wir werden für den Web Scraper zu Beginn folgende Importe benötigen:
import requests
from bs4 import BeautifulSoup
Der erste Schritt, den wir implementieren, ist das Abfragen der Webseite. Dazu nutzen wir die Requests-Bibliothek. In ihrer einfachsten Form sieht eine Methode zum Aufruf einer Webseite so aus:
Starten Sie das Programm mit F5 und rufen Sie die Funktion mit dem Parameter ‘https://en.wikipedia.org/wiki/List_of_mathematicians_born_in_the_ 19th_century’ auf.

Sie sollten die Antwort <Response [200]>, die für ein Objekt vom Typ Response steht, zurückerhalten. Die Zahl 200 entspricht dem HTTP-Code OK und bedeutet, dass die Anfrage erfolgreich war. Allerdings kann diese Anfrage auch fehlschlagen – beispielsweise bei einem Tippfehler, einer fehlenden Internetverbindung oder wenn die Seite den Zugriff verweigert
Wir wollen daher zum einen Exceptions wie NetworkError oder RequestError abfangen und zum anderen prüfen, ob das Ergebnis der Anfrage 200 OK ist. Insbesondere, wenn mehrere Webseiten dynamisch angefragt werden sollen, ist es wichtig solche Zugriffsfehler zu behandeln, damit die Gesamtausführung nicht durch einen fehlschlagenden Request unterbrochen wird. Außerdem prüfen wir, dass der Content-Type des Response HTML ist, und geben den Inhalt und nicht das gesamte Objekt zurück.
Führen Sie die Funktion einmal mit einer validen und einer invaliden URL aus und betrachten das Ergebnis.
Erfolgreicher Output:

Output mit behandeltem Fehler:

Als nächstes benötigen wir eine Funktion für den zweiten Schritt, nämlich dem Extrahieren der Informationen. Dazu nutzen wir BeautifulSoup. BeautifulSoup erstellt ein Objekt vom Typ BeautifulSoup, das das Dokument repräsentiert und einfach traversiert bzw. transformiert werden kann. Dazu wird der Konstruktor BeautifulSoup mit dem HTML- oder XML-Inhalt und einem Parameter für die Art Parser, der verwendet werden soll, aufgerufen. Wir wollen alle li-Elemente aus dem HTML extrahieren und deren Inhalte ausgeben und können dafür die .select()-Methode verwenden:
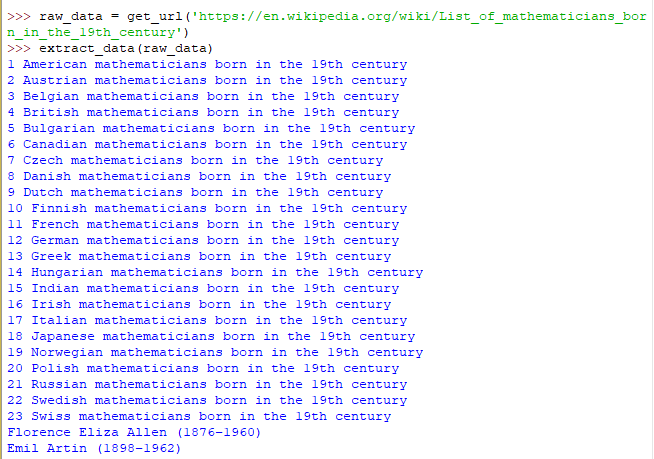
Dieser Output zeigt, dass wir durch das Sammeln der li-Elemente zwar alle Mathematiker erhalten, aber auch irrelevante Information wie die Gliederung des Dokuments. Das bedeutet, wir müssen einen Weg finden, den Inhalt der Elemente so zu filtern, dass wirklich nur die Mathematiker übrigbleiben. An dieser Stelle lohnt sich meist ein weiterer Blick in das HTML – oft sind Elemente mit Attributen oder Klassen versehen, durch die eine klarere Differenzierung möglich ist. Wäre beispielsweise jede Aufzählung in einem div-Element mit einem Namen oder einer Id, könnten wir das BeautifulSoup-Objekt gezielt nach diesen Eigenschaften durchsuchen:
raw_data.findAll('div', { 'class': 'foo'})
Leider ist das bei dem Wikipedia-Artikel nicht der Fall, wir müssen für die Aufbereitung also auf ein anderes Mittel zurückgreifen. Eine Möglichkeit dafür sind reguläre Ausdrücke.
Uns interessieren lediglich die Einträge der Form:
Name, (Geburtsjahr-Sterbejahr) [evtl. Zusatzinformation]
Dies lässt sich durch folgenden regulären Ausdruck darstellen:
.*\(\d{4}-\d{4}\).*
Der Ausdruck .* beschreibt, dass wir eine beliebige oder auch leere Zeichenkette erwarten. \( und \) sind escapte Klammern. Klammern können auch zur Formulierung des regulären Ausdrucks verwendet werden, an dieser Stelle suchen wir aber nach expliziten Klammerzeichen. Um das auszudrücken, wird der Backslash verwendet. Innerhalb der Klammern erwarten wir zwei vierstellige Zahlen, durch einen Bindestrich getrennt. Der Ausdruck \d steht für eine beliebige Ziffer, {4} beschreibt, dass wir genau 4 Ziffern suchen.
Um diesen regulären Ausdruck in Python anzuwenden, importieren wir die Bibliothek re. Diese muss nicht separat installiert werden, da sie im Gegensatz zu Requests oder BeautifulSoup bereits durch die Python-Installation vorliegt.
import re
Wir erweitern die Iteration über alle List Items um einen Vergleich mittels der .match()-Methode.
Führen Sie die Methode aus. Das Ergebnis sollte überraschend sein: Es sind nur zwei Einträge enthalten.

Ein erneuter Blick in das HTML zeigt uns, dass die Bindestriche dieser Einträge einen anderer Character haben als die restlichen. Gerade solche Feinheiten können bei Web Scraping oft auftreten und sind nicht immer offensichtlich. Daher ist es wichtig, sich während der Programmierung regelmäßig die Zwischenergebnisse anzusehen und auf Plausibilität zu prüfen.
Gehen Sie nun auf den Wikipedia-Artikel und kopieren den Bindestrich, damit er dem richtigen Zeichen entspricht. Erweitern Sie den regulären Ausdruck so, dass er beide Bindestriche findet:
.*\(\d{4}(–|-)\d{4}\).*
Die Ausgabe sollte nun deutlich mehr Einträge, insgesamt 155, beinhalten.
Zur weiteren Verarbeitung speichern wir alle für uns relevanten Einträge in einer Liste. Diesen Filterschritt selbst lagern wir in eine eigene Funktion aus:
Nachdem wir auf diese Weise alle Mathematiker extrahiert haben, können wir uns mit der eigentlichen Aufgabe beschäftigen, nämlich nur diejenigen zu ermitteln, die nicht 60 Jahre alt geworden sind. Dazu spalten wir die Zeichenkette in einzelne Teile:
Wir erhalten als Ergebnis dieses Codes pro Zeile sowohl den Namen als auch die Lebensspanne des jeweiligen Mathematikers. Um die Lesbarkeit zu erhöhen, können wir die Aufspaltung des Strings in eine eigene Methode parse_line auslagern und dort beide Werte zurückgeben:
Um erneut die Lesbarkeit des Codes zu verbessern, geben wir anstatt eines einfachen Tupels ein Objekt vom Typ namedtuple zurück. Ein namedtuple ist eine Wertmenge mit benannten Feldern.
from collections import namedtuple
LineContent = namedtuple('LineContent', 'name age_range')
Diese Definition, die am Anfang des Skriptes eingefügt wird, deklariert, dass es Objekte vom Typ LineContent gibt, die die Felder name und age_range besitzen.
So ergibt sich folgende Methode:
Jetzt fehlt lediglich eine Methode, um aus der verarbeiteten Zeile das Alter zu berechnen. Dazu muss die Information über das Geburts- und Sterbejahr, die aktuell in einem String steht, ermittelt werden. Der String wird dazu gesplittet und die Jahreszahlen in Integer umgewandelt und subtrahiert. Dabei gilt es zu beachten, dass verschiedene Trennzeichen vorkommen können:
Die einzelnen Funktionen müssen abschließend zu einem Ganzen zusammengefügt werden: Wir wollen einen Eintrag zuerst parsen, dann das Alter berechnen und schließlich die Zeile ausgeben, wenn das Alter unter 60 liegt.
Wir können grundsätzlich davon ausgehen, dass in den beiden Subroutinen parse_line und get_age kein Fehler auftritt, da wir die Zeilen mit einem regulären Ausdruck ermittelt haben. Liegen wir mit dieser Annahme allerdings falsch, würde die Ausführung einfach beendet werden. Daher sollte das Aufbereiten und Verarbeiten der Zeile ebenfalls mit einem try-except-Block versehen werden.
Um die Funktion mit jedem Eintrag durchzuführen, wird sie in der Iteration der parse_html-Methode aufgerufen.
Damit ist die Funktionalität vollständig implementiert. Als letztes soll der Web Scraper nun direkt beim Start des Skriptes ausgeführt werden.
Python funktioniert nicht wie andere Programmiersprachen nur, wenn es eine Main-Methode zum Einstieg gibt. Stattdessen wird das Script von oben nach unten abgearbeitet. Für die Ausführung wird ein Parameter __name__ festgelegt, der je nachdem ob das Skript von einer Kommandozeile aufgerufen, aus der IDLE gestartet oder importiert wurde, variiert. Wird das Script direkt ausgeführt, entspricht der Inhalt der Variablen __main__. Der Ausdruck
if __name__ == '__main__':
evaluiert daher zu True und der Code der If-Anweisung wird ausgeführt. Wird das Script hingegen importiert, ist der Inhalt von __name__ anders, sodass die Kondition nicht erfüllt und der Code der „Main-Methode“ nicht ausgeführt wird.
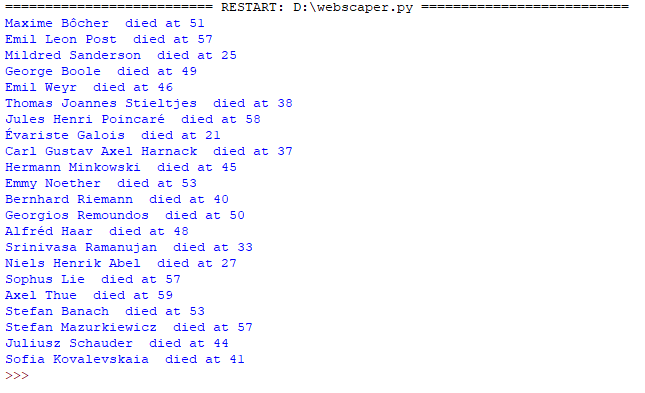
Führen Sie das Programm aus, nachdem Sie das If-Statement eingebaut haben, sollten Sie direkt das folgende Ergebnis sehen:
Anstatt einer einfachen Ausgabe wie dieser könnten Sie auch die Anzahl der Mathematiker, die jünger oder älter als 60 geworden sind, gegenüberstellen oder das Durchschnittsalter bzw. die Altersverteilung berechnen. Genauso ist es möglich, noch weitere Wikipedia-Artikel zu scrapen. So könnten Sie das Programm einmal über die Liste der Amerikanischen Mathematiker laufen lassen – beachten Sie aber, dass hier auch Mathematiker, die noch nicht gestorben sind, aufgeführt werden. Sie müssen das Programm also erweitern.
Zusammenfassung
Web Scraping bezeichnet das automatisierte Extrahieren von Informationen von einer oder mehreren Webseiten. Web Scraper sind ein guter Einstieg in das Gebiet der Data Science bzw. des Data Minings: Es gibt viele verschiedene Anwendungsgebiete und kleine Programme können ohne großen Aufwand implementiert werden. Eine der beliebtesten Sprachen dafür ist Python, denn insbesondere durch die Bibliotheken Requests und BeautifulSoup stellt diese Sprache alles, was für einen Web Scraper benötigt wird, sehr einfach zur Verfügung.
Um einen Web Scraper zu implementieren, müssen die Webseiten hinsichtlich des Inhalts, der extrahiert werden soll, untersucht werden. Hat man eine Strategie zur Datenextraktion ausgearbeitet, kann man mit der Umsetzung beginnen. Dabei gibt es zwei zentrale Schritte: Zuerst das Auslesen der rohen Daten und das anschließende Aufbereiten, um die gewünschte Information zu erhalten. Dazu können sowohl die HTML-Elemente selektiert und betrachtet als auch reguläre Ausdrücke verwenden werden. Abschließend werden die Informationen gespeichert oder weiterverarbeitet.
Quellcode:





Hallo an alle!
auch bei meinen Versuch ging nichts.
Durch Peter seinen Hinweis ,nochmal versucht ,nichts.
Dann hatte ich diese Zeichen in der URL ” ‘ ” durch ” ” ” ersetzt !!!!!!
!!! erst dann klappte alles ! im ersten py1_1.py
und dann auch im py13_1.py !!
Also ,ich weiss ja ,man soll lernen ,aber das war ein grober Fehler von Euch .
Der hätte nicht passieren sollen.
Aber trotzdem Danke für diesen Beitrag .
Guten Tag,
Vielen Dank für Ihren Hinweis!
Wir werden diesen Fehler prüfen und dementsprechend in unserem Blogartikel korrigieren. Bitte entschuldigen Sie die Unstimmigkeiten.
Olena vom BMU Verlag
Hallo, das kleine erste Beispiel funktioniert nur mit einem zusätzlichen Printbefehl, sonst gibt es (zumindest bei mir) keinen .
Z.B. so:
import requests
from bs4 import BeautifulSoup
def get_url(url):
response = requests.get(url)
return response
a = get_url(‘https://en.wikipedia.org/wiki/List_of_mathematicians_born_in_the_19th_century’)
print(a)
Liebe Ersteller dieses Internetbeitrags,
in den Python Zeilen unter “Als nächstes benötigen wir eine Funktion für den zweiten Schritt, …” fehlt ein “s” bei [def extract_data(reponse_content):]
welches [def extract_data(response_content):] heißen müsse.
Hallo Christopher,
Vielen Dank für Ihren Hinweis!
Wir haben es gerade korrigiert. Jetzt sollte alles passen.