 PHP und MySQL für Einsteiger
PHP und MySQL für Einsteiger 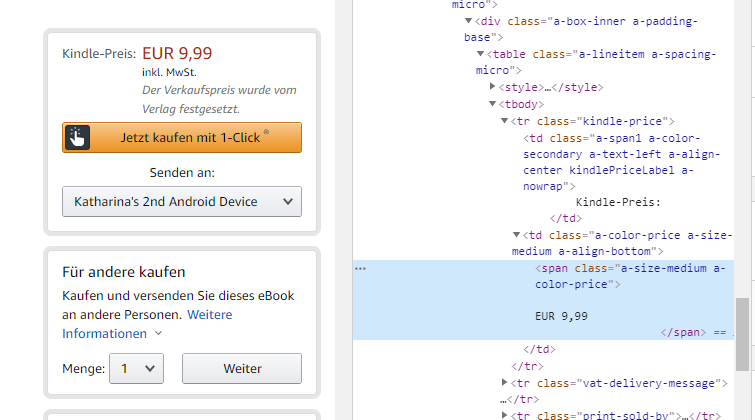
Amazon Preistracker in Python
Python ist eine Sprache, mit der kleine Tools, die den Alltag erleichtern, schnell und einfach geschrieben werden können. Insbesondere das Scraping von Webseiten geht mit Python sehr einfach, wie wir bereits in unserem Tutorial Web Scraping mit Python gezeigt haben. Auch in diesem Tutorial wollen wir Python nutzen, um die Inhalte von Webseiten automatisiert auszulesen und zu verarbeiten. Dazu werden wir einen Preistracker schreiben, der regelmäßig die Preise auf Amazon für ausgewählte Produkte prüft und eine E-Mail versendet, wenn ein bestimmtes Preislimit unterschritten wird. Die Produkte und Preise werden wir in einer separaten Datei konfigurieren. Schlussendlich werden wir einen Windows Task anlegen, der das Programm einmal an Tag ausführt. Dieses Tutorial richtet sich an Leser, die Grundkenntnisse in Python und HTML haben.
Was ist Web Scraping?
Grundsätzlich bezeichnet man als Web Scraping das automatisierte Auslesen, Aufbereiten und Analysieren von Daten aus dem Internet. Die wichtigsten Schritte sind dabei das Herunterladen der Inhalte, die man genauer betrachten möchte, die anschließende Transformation der Daten in ein nutzbares Format und abschließend die Verwendung der Daten für ihren vorgesehenen Zweck. Eine ausführliche Einführung in Web Scraping finden Sie auch in dem verlinkten Artikel.
Python stellt viele Bibliotheken wie beautifulsoup oder requests zur Verfügung, mit denen Web Scraper sehr einfach implementiert werden können. Da Python selbst die Umsetzung von kleinen Projekten mit wenig Overhead ermöglicht, ist die Sprache sehr beliebt für Web Scraping.
Vorbereitung
Die Vorbereitung für das Projekt besteht aus drei Schritten: Zuerst müssen wir Python und einige Module installieren, anschließend benötigen wir (optional) einen URL-Shortener für Amazon und schlussendlich werden wir die Produktseiten von Amazon genauer inspizieren.
Schritt 1: Python und Bibliotheken installieren
Für dieses Tutorial benötigen Sie eine Python 3-Installation. Den Installer können Sie hier herunterladen. Erlauben Sie, dass Python dem Pfad hinzufügt wird und starten Sie danach die Standard-Installation.
Neben den bereits in der Basisinstallation enthaltenen Modulen werden wir beautifulsoup und requests benötigen. Beautifulsoup ist eine Bibliothek, mit der HTML und XML-Dokumente geparsed werden können, um auf die einzelnen Elemente zuzugreifen. Requests ist eine Bibliothek zur Versendung von HTTP-Anfragen.
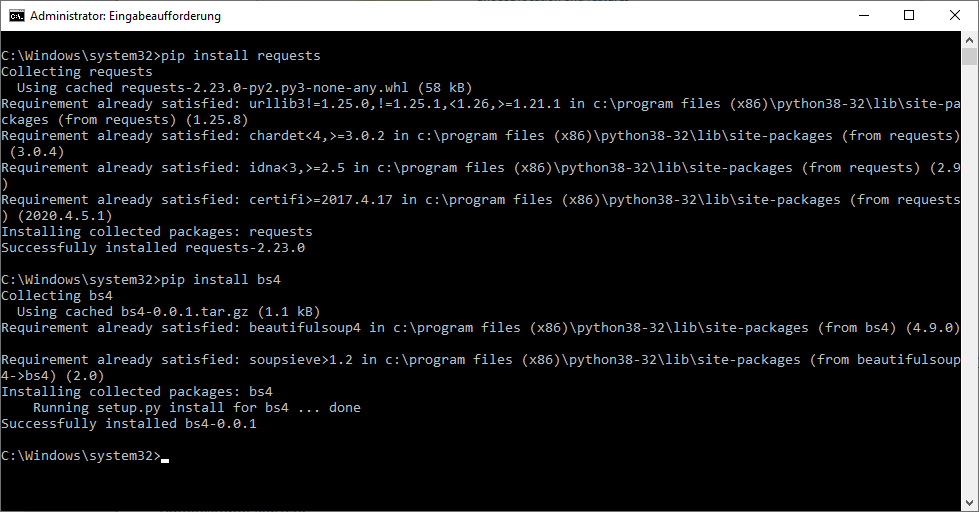
Beide Bibliotheken können Sie mit pip, dem Python Package Manager, herunterladen. Pip sollte direkt mit Python zusammen installiert worden sein. Um pip zu nutzen, öffnen Sie eine Kommandozeile als Administrator und geben Sie die Befehle:
pip install requests
pip install bs4
ein.
Schritt 2: Amazon URL-Shortener zum Browser hinzufügen
Das ist auch schon alles an Software, die Sie zum Entwickeln benötigen. Um besser mit den Amazon-URLs umgehen zu können, ist es außerdem sinnvoll im Browser einen Amazon URL-Shortener zu installieren. Ein solches Plugin gibt es für die meisten Browser kostenlos. Es kürzt die recht langen Amazon-Links in URLs der Form https://amzn.to/1aBC2de, mit denen deutlich leichter umgegangen werden kann. Zudem fallen Sonderzeichen wie $ oder & weg, was auch das Handling im Code später vereinfachen wird. Das Plugin für Chrome finden Sie hier, das Plugin für Firefox hier.
Schritt 3: Die Webseite inspizieren
Der letzte Schritt der Vorbereitung ist das Inspizieren der Webseite, damit wir wissen, wo die Daten, für die wir uns interessieren, stehen. Dazu können Sie den Inspektor Ihres Browsers verwenden. Klicken Sie mit der rechten Maustaste an irgendeine Stelle auf der Webseite und wählen sie Inspect oder Untersuchen. Dadurch öffnet sich ein separates Fenster, in dem Sie die HTML-Struktur, den Network Traffic, Ausgaben oder JavaScript und CSS-Dateien der Seite genauer betrachten können.
Mit einem Klick auf den Pfeil in der oberen Ecke des Inspektors können Sie ein Element auf der Oberfläche direkt selektieren. Dadurch springen Sie in der HTML-Darstellung an die Stelle, die das Element enthält.

Öffnen Sie nun ein Produkt auf Amazon, das Sie interessiert – wir verwenden in diesem Tutorial eine schwenkbare Wandhalterung. Die für uns relevanten Informationen sind der Name des Produktes und sein Preis.
Inspizieren Sie zuerst den Namen: Dieser befindet sich in einem span-Element mit der ID productTitle.
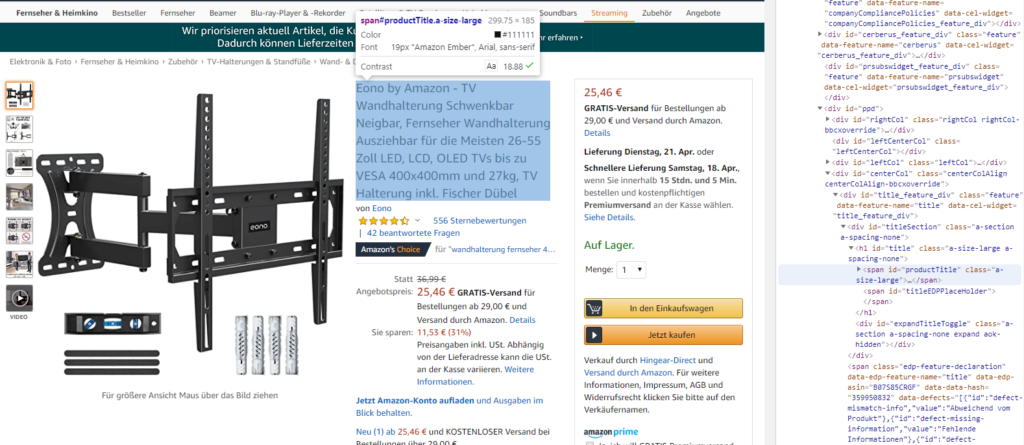
Der Preis kann sich an zwei Stellen befinden, je nachdem, ob es sich um einen Deal oder den normalen Preis bei Amazon handelt. Deals stehen in einer span mit der ID priceblock_dealprice, normale Preise haben die ID priceblock_ourprice.
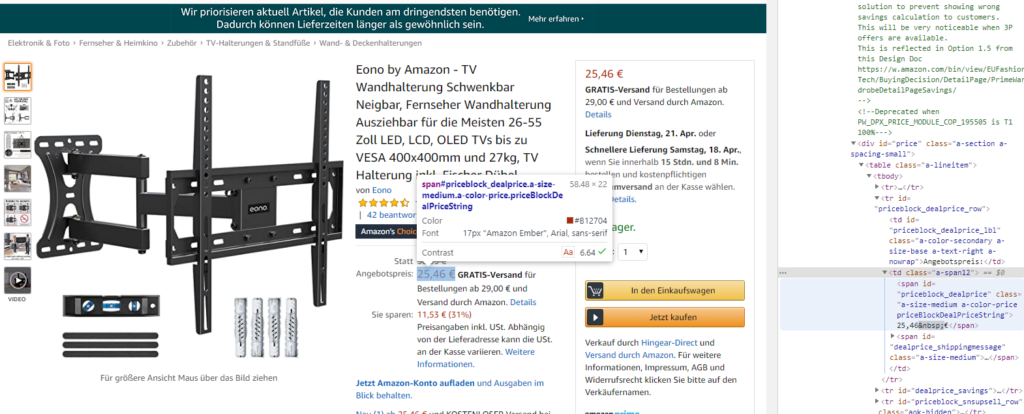
Eine Ausnahme sind Amazon Books und Produkte, die nur über Dritthändler angeboten werden. Hier befindet sich der Preis nur auf der rechten Seite in einer span, die keine eindeutige ID besitzt:
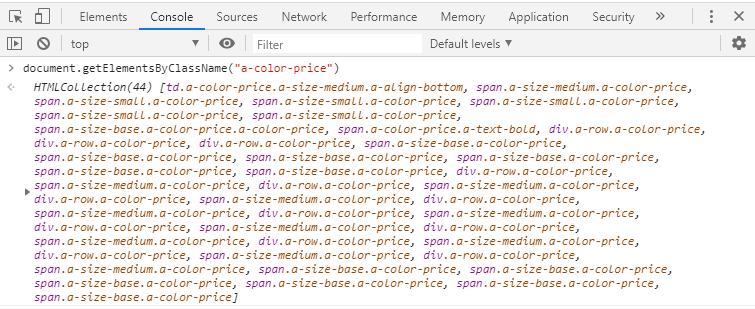
Sie können über die Konsole des Inspektors herausfinden, wie viele Elemente mit der Klasse dieser span auf der Seite existieren:
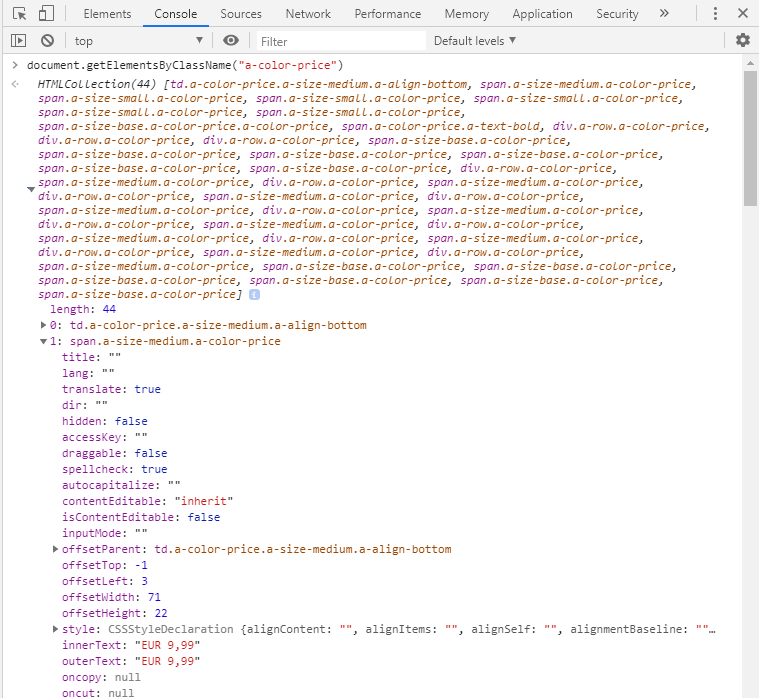
Wenn Sie sich diese Elemente genauer ansehen, können Sie feststellen, dass der gesuchte Preis direkt im ersten span-Element enthalten ist.
Damit wissen wir nun, wo wir die für uns interessante Information auf den Artikelseiten finden, und können mit der Implementierung des Web Scrapers beginnen.
Implementierung des Web Scrapers
Wir werden den Web Scraper in vier Schritten implementieren: Zuerst werden wir die Webseite herunterladen und den Produktnamen und -preis extrahieren. Anschließend werden wir eine E-Mail über Google Mail verschicken, falls der Preis niedriger als unser Preislimit ist. Danach werden wir die URLs und Preislimits in eine separate Datei auslagern. Schlussendlich werden wir das Skript mit einem täglichen Windows Task schedulen.
Schritt 1: Webseite herunterladen und Informationen extrahieren
Öffnen Sie zum Programmieren die Python IDLE oder einen Python Editor Ihrer Wahl. Der erste Schritt beim Web Scraping ist das Herunterladen der Webseite, um die relevante Information extrahieren zu können. Dazu werden wir die URL und den Zielpreis vorerst als Konstanten im Code festlegen.
URL = 'your_url' TARGET_PRICE = your_price (e.g. 10.0)
Die URL sollten Sie bereits über das Plugin im Browser gekürzt haben:
Anschließend wollen wir die Webseite herunterladen. Dazu importieren wir das Modul requests und nutzen die Funktion requests.get(URL). Führen Sie den Code
einmal aus.
Sie sollten einen String, der eine HTML-Seite repräsentiert, erhalten.

Kopieren Sie den Inhalt in eine Datei amazon.html und öffnen Sie sie. Sie werden feststellen, dass wir nicht auf der Produktseite landen, sondern auf einer Seite, die uns auffordert, ein Captcha einzugeben.
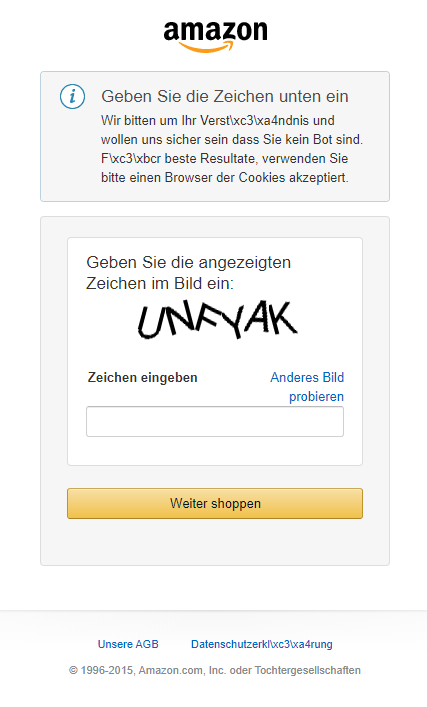
Das passiert, weil wir bei der Anfrage keinen User-Agent Header mitgegeben haben. Dieser wird benötigt, damit Amazon das anfragende Gerät identifizieren kann. Der Browser schickt diesen Header automatisch mit, unser Programm nicht.
Um auf der Produktseite zu landen, müssen wir einen entsprechenden Header hinzufügen. Googlen sie dazu „my user agent“ und kopieren Sie das Ergebnis in eine Konstante HEADERS im Code. Übergeben Sie der get-Methode den Header über den Parameter headers.
Das Ergebnis sollte nun deutlich länger sein:

Als nächstes wollen wir die Webseite parsen. Dazu importieren wir beautifulsoup und nutzen den Befehl BeautifulSoup(string, parser) zum Parsen des Inhalts der Webseite.
Sie müssen die html5lib gegebenenfalls über pip mit dem Befehl
pip install html5lib
nachinstallieren.
Das Ergebnis dieses Aufrufs ist ein Parsetree, über den die verschiedenen Elemente des HTML-Strings page.content gesucht werden können.
Wir suchen nun die Elemente anhand der Eigenschaften, die wir vorhin über den Inspektor ermittelt haben:
Es kann sein, dass es für den Artikel aktuell keinen Deal gibt. In diesem Fall lesen wir stattdessen den normalen Preis aus.
Falls auch dieser Preis nicht vorhanden ist, suchen wie die erste span, die die Klasse a-color-price hat. Dazu können Sie ebenfalls die find-Methode verwenden, da diese grundsätzlich immer nur ein Element zurückgibt:
Wenn Sie das gesamte Dokument nach einer bestimmten Klasse durchsuchen wollen, können Sie stattdessen die Methode find_all verwenden.
Geben Sie anschließend den Inhalt der beiden Variablen title_span und price_span aus:
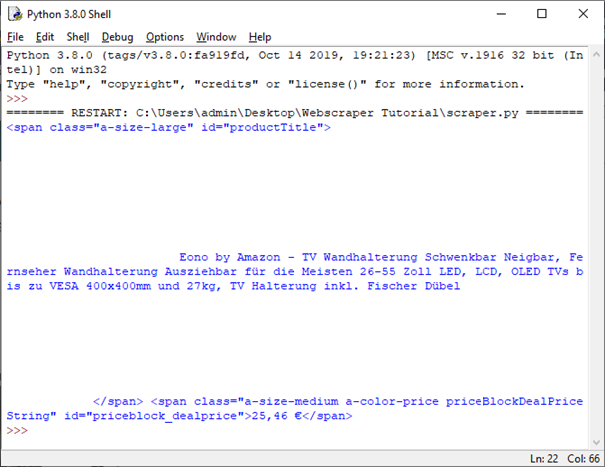
Wir erhalten zwei span-Elemente, deren Inhalt wir nun weiterverarbeiten können. Für den Titel ist das relativ einfach. Mit der Anweisung
name = title_span.get_text().strip()
lesen wir erst den Inhalt der span aus und entfernen dann Leerzeichen vorne und hinten. Wir sollten allerdings noch eine Prüfung hinzufügen, ob wir tatsächlich ein entsprechendes Element im HTML gefunden haben. Wenn title_span None ist, würde Python die Ausführung sonst mit einem Fehler beenden.
Um den Preis aufzuarbeiten, müssen wir ebenfalls zuerst den Inhalt der span mit der Methode get_text() holen. Wir benötigen allerdings einen Float, also eine Gleitkommazahl, und keinen String – sonst können wir später keinen Vergleich mit unserem Zielpreis durchführen.
Schreiben wir dazu eine Methode parse_price(price_text), der wir den Preisstring übergeben.
Diese Methode erhält den String aus der span als Eingabewert und entfernt zuerst die Einheit, entweder in Form des Eurozeichens oder als String EUR, und das Leerzeichen. Danach werden Punkte, die bei Preisen über 1.000 € auftreten, entfernt. Die Kommastelle ist für das deutsche Amazon durch ein Komma dargestellt. Damit wir den Wert in einen Float umwandeln können, müssen wir das Komma durch einen Punkt ersetzen. Beachten Sie, dass für das amerikanische Amazon Tausenderstellen mit einem Komma und Kommastellen mit einem Punkt dargestellt werden – dieses Format kann die Funktion nicht verarbeiten. Abschließend wandeln wir den String in einen Float um und geben ihn zurück.
Starten Sie das Programm und testen Sie die Funktion mit verschiedenen Eingabewerten.
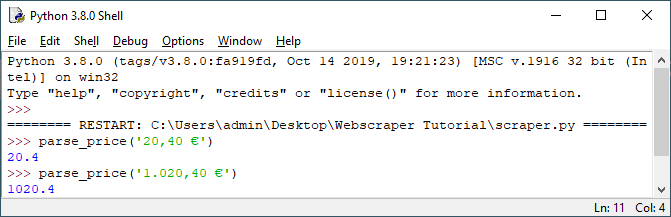
Insgesamt ergibt sich für die Ermittlung des Preises der Code:
Nutzen sie diesen geparsten Wert nun für eine Prüfung, ob der aktuelle Preis unter Ihrem Zielpreis liegt. In diesem Fall wollen wir die URL und den Preis vorerst nur ausgeben.
Insgesamt sollten Sie nun folgenden Code geschrieben haben:
Starten Sie das Programm mit einem Zielpreis unter und über dem tatsächlichen Preis Ihres gewählten Artikels – je nachdem sollten Sie eine Ausgabe erhalten oder nicht.
Schritt 2: E-Mail versenden
Als nächstes wollen wir uns für den Fall, dass unser Zielpreis erreicht wurde, selbst eine E-Mail senden. Zu diesem Zweck benötigen Sie eine Adresse bei Google Mail. Wir werden in unserem Code sowohl die Adresse als auch das Passwort verwenden. Damit Sie Ihr Passwort im Code nicht im Klartext schreiben müssen, können Sie bei Google ein eigenes Passwort für eine App und ein Zielgerät erstellen.
Dazu muss Zwei-Faktor-Authentifizierung aktiviert sein. Aktivieren Sie diese in Ihrem Google Account unter Sicherheit > Bei Google anmelden > Bestätigung in zwei Schritten.
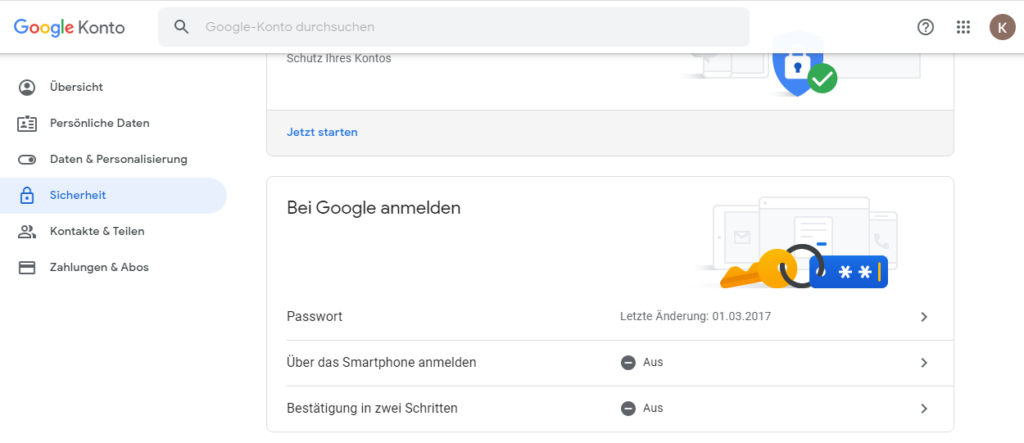
Anschließend können Sie im selben Abschnitt App-Passwörter festlegen.
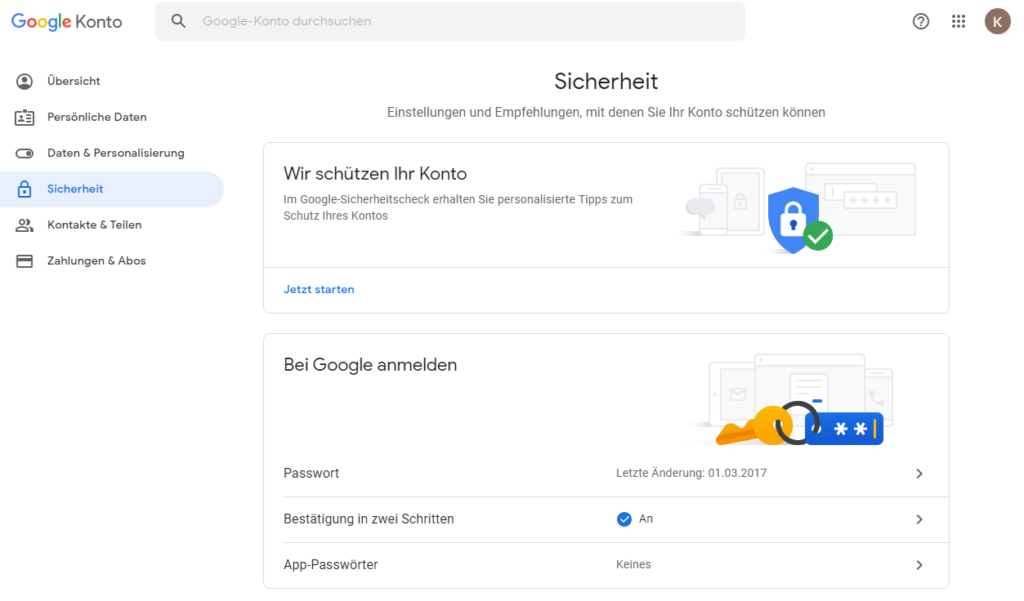
Klicken Sie auf den kleinen Pfeil der Zeile App-Passwörter und wählen Sie anschließend ein Passwort für die Anwendung E-Mail und das Gerät, auf dem Sie entwickeln, beispielweise einem Windows-Computer:
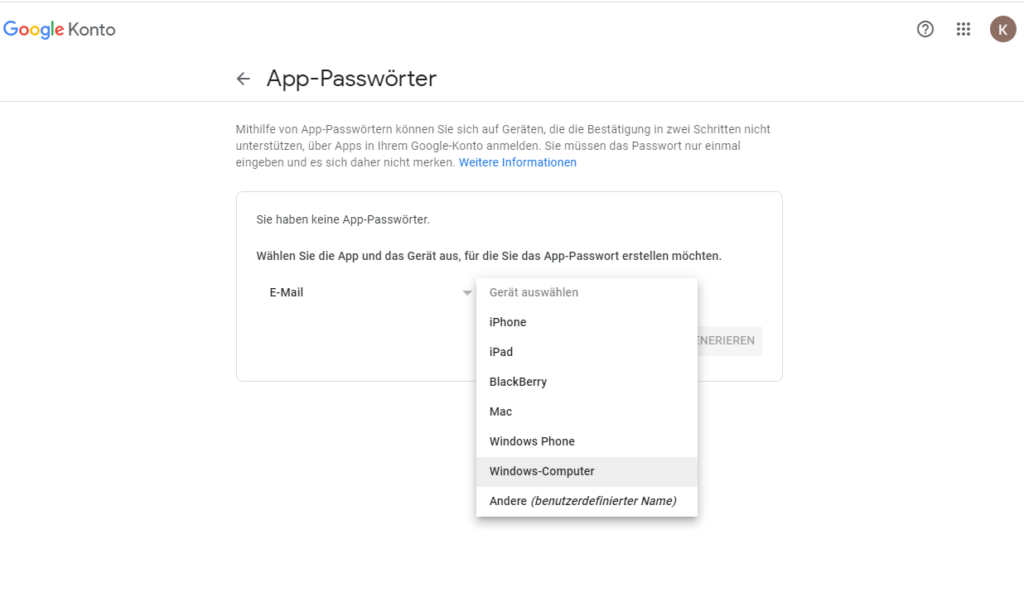
Nachdem Sie auf Generieren geklickt haben, erhalten Sie ein 16-stelliges Passwort. Kopieren Sie dieses. Nun können wir E-Mail-Adresse und Passwort als Konstanten im Code festlegen.
MAIL_ADDRESS = 'your.mail@gmail.com'
PASSWORD = 'generated_password'
Das Versenden von E-Mails in Python ist dank der Bibliothek smtplib (kurz für SMTP Library) relativ einfach. Die Bibliothek muss nicht separat installiert werden. SMTP steht für Simple Mail Transfer Protocol und ist das Standardprotokoll für den Versand oder die Weiterleitung von E-Mails.
Mit dem Befehl smtplib.SMTP(host, port) bauen Sie eine SMTP Verbindung auf. Für Google Mail werden der Host smtp.gmail.com und der Port 587 als Parameter übergeben.
Auf dieser Verbindung können verschiedene Befehle aufgerufen werden. Zuerst rufen wir die Funktion ehlo() auf. Damit identifizieren wir uns als ESMTP (Extended SMTP)-Client. Anschließend rufen wir die Funktion starttls() auf. Damit wechselt die Verbindung in den TLS (Transport Layer Security)-Modus. Das ist notwendig, wenn Sie über Google Mail E-Mails verschicken wollen. Danach sollte die Methode ehlo() ein weiteres Mal aufgerufen werden. Anschließend können wir uns einfach mit der E-Mail-Adresse und dem eben generierten Passwort einloggen.
Insgesamt ergibt sich so eine Methode send_email(name, price), die als Parameter die Werte erhält, die wir gerade aus dem HTML ausgelesen haben. Diese Parameter werden wir gleich verwenden, um den Inhalt der E-Mail zu generieren.
Erstellen wir nun den Inhalt der E-Mail, indem wir erst den Betreff und dann die Nachricht selbst formatieren. Zur Formatierung können wir f-Strings verwenden. In einem f-String können Variablen in geschweiften Klammern direkt verwendet werden, wodurch sich die Lesbarkeit im Code erhöht.
Die gesamte Nachricht sollte wie folgt formatiert werden, damit der Betreff und der Nachrichtenkörper getrennt werden:
message = f'Subject: {subject}\n\n{body}'Abschließend versenden wir die E-Mail mit der Methode sendmail(from, to, message) und beenden die Verbindung.
Diese Funktion wird anstelle des print(URL, name, price)-Aufrufs verwendet.
Insgesamt sollten Sie nun etwa folgenden Code geschrieben haben:
Zuletzt sollten wir Code zum Auslesen der Artikelinformation ebenfalls in eine Methode get_article_details(url) auslagern. Der Code zum Aufruf der Methoden wird aus dem einfachem Skriptablauf entfernt und stattdessen unter der Bedingung if __name__ == ‘__main__’ ausgeführt. Diese Bedingung evaluiert zu true, wenn das Programm normal gestartet wird. Wird das Skript aber beispielsweise als Modul importiert, wird der der Code nicht aufgerufen.
Führen Sie den Code mit eine passenden Zielpreis aus und prüfen Sie, ob Sie eine E-Mail erhalten haben:
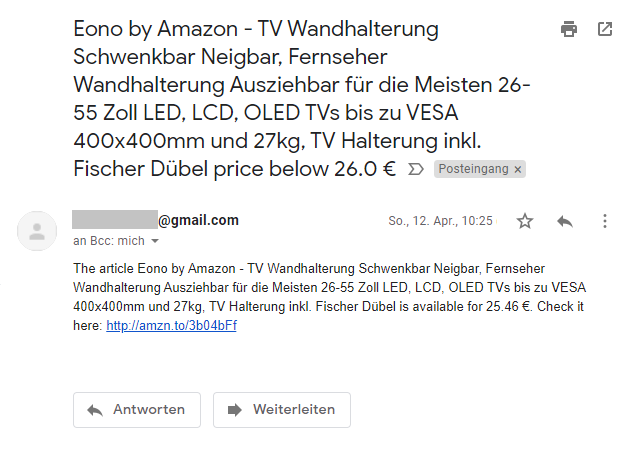
Schritt 3: Konfigurieren der Artikel in einer externen Datei
Mit diesem Code können Sie nun einmal den Preis des als URL festgelegten Artikels abfragen und gegebenenfalls eine E-Mail verschicken. Es wäre allerdings besser, wenn Sie mehrere Artikel prüfen oder nachträglich das Preislimit zu den Artikeln ändern könnten, ohne jedes Mal den Code anpassen zu müssen. Daher werden wir im nächsten Schritt mehrere Artikel und Preise in einer JSON-Datei festlegen und auslesen.
JSON steht für JavaScript Object Notation und ist eine Möglichkeit, Objekte oder Listen menschenlesbar aufzuschreiben. Ein Objekt wird in geschweiften Klammern dargestellt und besitzt Schlüssel-Wert-Paare, die einem Attribut des Objektes mit dem Schlüsselnamen einen Wert zuweisen. Eine Liste wird mit eckigen Klammern notiert.
Viele Sprachen, darunter auch Python, stellen JSON-Parser zur Verfügung, mit denen zu der Notation konforme Zeichenketten automatisch in Objekte umgewandelt werden können. Daher ist JSON gut geeignet, Konfigurationsdateien zu erstellen.
Wir definieren, dass unsere JSON-Datei eine Liste mit URL-Preis-Objekten mit den Schlüsseln url und target_price enthalten soll:
Speichern Sie die Liste als Datei articles.json neben dem Pythonskript.
Wir wollen die Datei nun im Code auslesen. Dazu verwenden wir das Modul json.
In der ersten Zeile der Funktion lesen wir eine Textdatei mit dem als Konstante festgelegten Dateinamen im Lese-Modus (r) aus. Anschließend wird der Inhalt als JSON-Strings geladen – das ist auch schon alles, was zu tun ist.
Probieren Sie die Methode einmal aus:
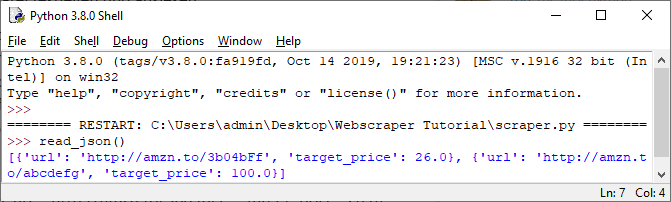
Wir erhalten eine Liste, die alle Artikel der Datei enthält, und mit der wir nun weiterarbeiten können.
Bevor wir fortfahren wäre es allerdings sinnvoll, die wichtigsten Fehler, die beim Auslesen der Datei auftreten können, zu behandeln. Diese ist zum einen ein FileNotFoundError, falls die Datei nicht existiert, und ein json.decoder.JSONDecodeError, falls der Inhalt der Datei vom JSON-Modul nicht geladen werden kann. In diesem Fall wollen wir eine leere Liste zurückgeben und eine Meldung ausgeben.
Anschließend validieren wir, dass die Liste nur Objekte enthält, die wir verarbeiten können. Ansonsten finden das Programm später beispielsweise einen Key durch einen Tippfehler nicht und Python beendet die Ausführung.
Wir schreiben also eine Methode validate_articles(articles), der wir alle Artikel, die erfolgreich geparsed wurden, übergeben. Zuerst prüfen wir für jeden Artikel, dass die Keys url und target_price vorhanden sind. Danach prüfen wir, dass die URL zumindest ein Amazon-Link und der Preis ein Float ist. Wird eine dieser Bedingungen nicht erfüllt, überspringen wir den Artikel, sonst fügen wir ihn den validen Artikeln hinzu.
Da wir nun direkt mit Artikelobjekten arbeiten können, können wir die Methodensignatur für die get_article_details-Methode ändern. Wir übergeben den Artikel, prüfen, ob es eine URL gibt, und schreiben die Rückgabewerte direkt an den Artikel.
Die Methode get_article_details kann nun für jeden Artikel aufgerufen werden. Außerdem können wir die Konstanten URL und TARGET_PRICE entfernen.
Abschließend passen wir auch die send_email-Methode so an, dass sie das komplette Objekt mit den Artikelinformationen erwartet und deren Werte zum Erstellen des Nachrichteninhalts verwendet.
Insgesamt sollte der Code nun so aussehen:
Damit ist die Implementierung abgeschlossen.
Schritt 4: Das Programm regelmäßig ausführen
Der Preistracker lohnt sich allerdings nur, wenn er die Preise auch regelmäßig prüft. Eine Möglichkeit dazu wäre, das Programm jeden Tag selbst zu starten oder eine While-Schleife zu implementieren, die täglich die Methode aufruft und sonst mit time.sleep(seconds) schläft. Dazu müsste der Prozess aber permanent laufen.
Besser ist es, einen Windows Task einzurichten. Mit einem solchen Task können Sie festlegen, dass beispielsweise einmal täglich oder wöchentlich ein bestimmtes Programm ausgeführt werden soll. Dazu benötigen Sie eine Batch-Datei, die Ihr Programm aufruft. Eine Batch-Datei enthält Kommandozeilenbefehle, die beim Starten der Datei nacheinander abgearbeitet werden.
Um eine solche Datei zu erstellen, legen Sie ein neues Textdokument an, das Sie beispielsweise pricetracker.bat nennen. Wichtig ist, dass die Datei nicht mehr die Endung .txt sondern .bat hat. Diese Datei muss die Zeile:
python <Pfad zu Ihrem Skript>
enthalten. Damit das Skript funktioniert, muss Python in der PATH-Variable Ihrer Umgebungsvariablen hinzugefügt sein.
Führen Sie die Datei mit einem Doppelklick aus. Es sollte sich kurz eine Kommandozeile öffnen, die sich wieder schließt, wenn die Ausführung des Programms abgeschlossen ist. Sie können prüfen, ob das Programm funktioniert hat, indem Sie Ihre E-Mails checken.
Nun müssen wir die Batch-Datei in einem Task schedulen. Diese Funktion finden Sie unter Systemsteuerung > System und Sicherheit > Aufgaben planen.
Wählen Sie die Option Einfache Aufgabe erstellen
Anschließend können Sie einen Namen, ein Zeitintervall und das zu startende Skript oder Programm festlegen.
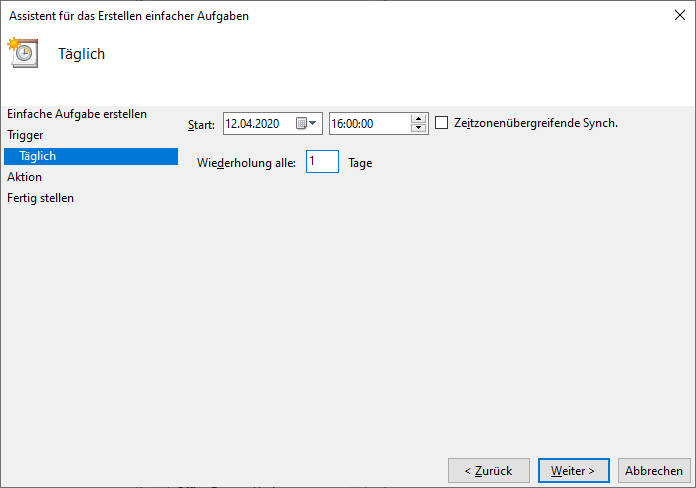
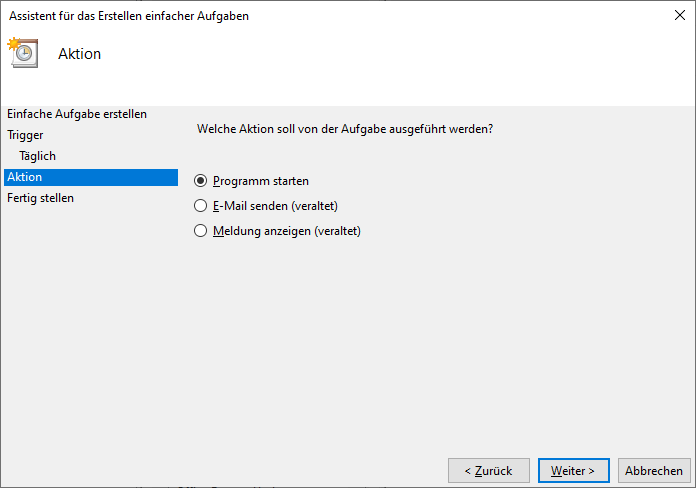
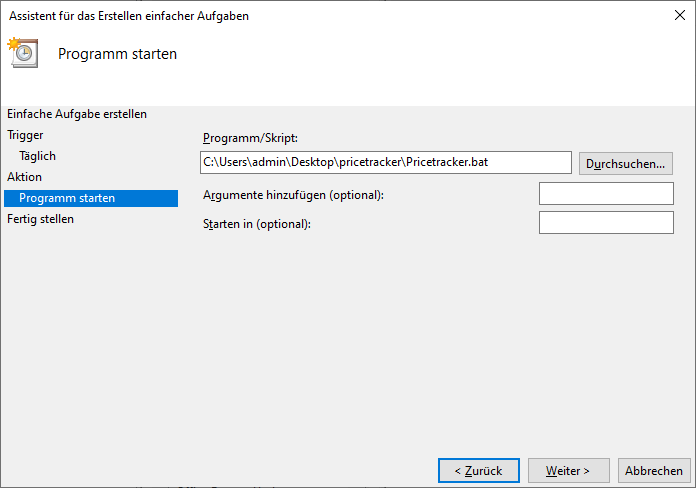
Das war es auch schon – Ihr Programm startet nun täglich zur festgelegten Zeit.
Zusammenfassung und Weiterentwicklung
In diesem Tutorial haben wir einen Web Scraper geschrieben, der Artikel bei Amazon abruft und prüft, ob diese ein bestimmtes Preislimit unterschritten haben. Dazu haben wir Amazon Webseiten mit dem Inspektor des Browsers untersucht.
Für den Fall, dass der Wunschpreis erreicht wurde, wird eine E-Mail über Google Mail versendet. Dazu stellen wir eine ESMTP-Verbindung her.
Die Artikel und Wunschpreise können über eine Datei im JSON-Format konfiguriert werden, ohne, dass das Skript selbst bearbeitet werden muss.
Zuletzt haben wir für den Web Scraper einen Windows Task eingerichtet, sodass er einmal am Tag von selbst ausgeführt wird.
Wenn Sie an dem Programm noch weiterarbeiten wollen gibt es dazu verschiedene Möglichkeiten: Sie können statt einer E-Mail pro Artikel eine E-Mail mit allen Artikeln versenden. Es wäre auch möglich, die Preise pro Tag zu speichern, um so später einen Preisgraph zu erstellen oder die Daten anderweitig auszuwerten. Zuletzt können Sie den Preis über einen regulären Ausdruck ermitteln oder den Algorithmus so anpassen, dass er auch für das amerikanische oder englische Amazon funktioniert.







Hallo,
die Funktion beim Verbindungsaufbau zum Mail-Server heißt “ehlo” nicht “elho”.
Gruß
Marlow
Hallo Marlow,
Danke für Ihren Kommentar!
Wir werden es prüfen und dementsprechend korrigieren.
Mit freundlichen Grüßen,
Olena Zakrytna
BMU Media GmbH